How to add swap to CoreOS on Azure?
Just a little while ago we needed to add swap to our CoreOS VMs on Azure but we didn't find a straightforward instructions how to do that.
Hopefully, it will come handy for people that are searching for this ;)
Instructions
Open waagent config file:
sudo vim /usr/share/oem/waagent.conf
add (or uncomment) lines
ResourceDisk.Format=y
ResourceDisk.Filesystem=ext4
ResourceDisk.MountPoint=/mnt/resource
ResourceDisk.EnableSwap=y
ResourceDisk.SwapSizeMB=4096
and now restart waagent
sudo systemctl restart waagent
If you happened to follow this tutorial, you gonna have an unstable system that's prone to freezing. Don't do that.
Links
Android Lifecycles Cheat Sheet
We've put together a simple cheat sheet that summarizes Android's Activity and Fragment lifecycles in one place.
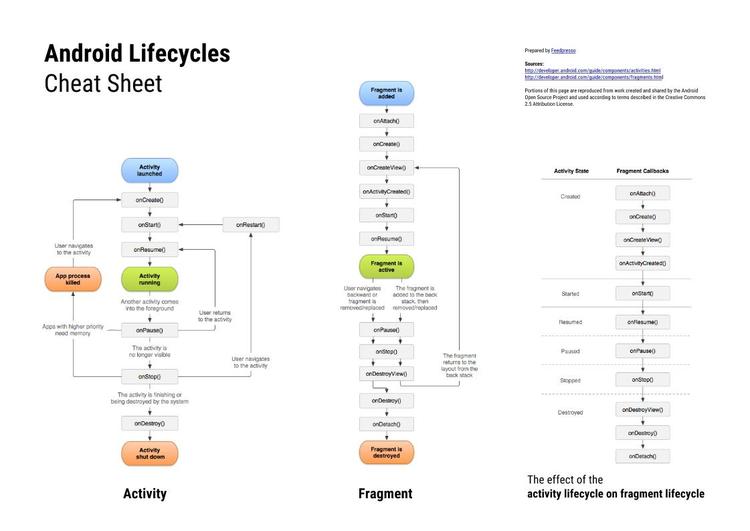
All of the diagrams come from the Android Developers portal, but having them all in one place has proved to be useful for us time and time again, so we decided to share. Let us know if you find this helpful!
Why you should use RxJava in Android a short introduction to RxJava
In most Android applications, you are reacting to user interactions (clicks, swipes and etc.) while doing something else in the background (networking).
Orchestrating all of this is a hard thing and could quickly turn into an unmanageable code mess.
For example, it isn't trivial to send a request to a database over network and after it completes start fetching user messages and preferences at the same time, and after all of that is complete show a welcome message.
This is a case where RxJava (ReactiveX) excels - orchestrating multiple actions that happen due to certain events in the system.
Using RxJava you will be able to forget callbacks and hellish global state management.
Why?
Let's get back to the example:
send a request to a database over network and after that completes start fetching his messages and his preferences at the same time, and after all of that is complete - show a welcome message.
If this is dissected, there will be these main parts that all happen in the background:
- Fetch a user from database
- Fetch user settings and user's messages at the same time
- Combine results from both responses in to one
To do the same in Java SE and Android, you are going to need to use:
- 3-4 different AsyncTasks
- Create a Semaphore, that will wait until both of the requests (settings and messages) will complete
- Object-level fields to store the results
It can be already seen, that this involves management of state and playing with some locking mechanisms in Java.
All of that can be avoided with RxJava (see examples below) - everything can be expressed as a flow in one place based on a functional paradigm (see this).
Quick start in Android studio
To get libraries that you are most likely to need in your project, in your build.gradle insert these lines:
compile 'io.reactivex:rxjava:1.1.0'
compile 'io.reactivex:rxjava-async-util:0.21.0'
compile 'io.reactivex:rxandroid:1.1.0'
compile 'com.jakewharton.rxbinding:rxbinding:0.3.0'
compile 'com.trello:rxlifecycle:0.4.0'
compile 'com.trello:rxlifecycle-components:0.4.0'
These will include:
- RxJava - a core ReactiveX library for Java.
- RxAndroid - RxJava extensions for Android that will help you with Android threading and Loopers.
- RxBinding - this will provide bindings between RxJava and Android UI elements likes Buttons and TextViews
- RxJavaAsyncUtil - helps you to glue code between Callables and Futures.
Example
Let's start with an example:
Observable.just("1", "2")
.subscribe(new Action1<String>() {
@Override
public void call(String s) {
System.out.println(s);
}
});
Here we created an Observable that will be emit two items 1 and 2.
We subscribed to the observable and once receive an item, it will be printed out.
Some details
Observable is something that you can subscribe to to listen for the items that the observable will emit. They can be constructed in many different ways. However, they usually don't begin emitting items until you subscribe to them.
After you subscribe to an observable, you get a Subscription. The subscription will listen for the items from observable until it marks itself as completed or, otherwise, it will continue indefinitely (a very rare case).
Furthermore, all of these actions are going to be executed on the main thread.
Expanded example
Observable.from(fetchHttpNetworkContentFuture())
.subscribeOn(Schedulers.io())
.observeOn(AndroidSchedulers.mainThread())
.subscribe(new Action1<String>() {
@Override
public void call(String s) {
System.out.println(s);
}
}, new Action1<Throwable>() {
@Override
public void call(Throwable throwable) {
throwable.printStackTrace();
}
});
Here we can see a few new things:
.subscribeOn(Schedulers.io())- it will make the Observable to do its waiting and computations on a ThreadPool that's dedicated for I/O (Schedulers.io())..observeOn(AndroidSchedulers.mainThread())- makes subscriber action to execute its result on Android's main thread. This is needed if one wants to change anything on Android UI.- A second argument to
.subscribe()- introduces an error handler for subscription in case something goes wrong. It's something that should be present almost always.
Managing complicated flow.
Remember the complicated flow we described initially?
Here is how it would look with RxJava:
Observable.fromCallable(createNewUser())
.subscribeOn(Schedulers.io())
.flatMap(new Func1<User, Observable<Pair<Settings, List<Message>>>>() {
@Override
public Observable<Pair<Settings, List<Message>>> call(User user) {
return Observable.zip(
Observable.from(fetchUserSettings(user)),
Observable.from(fetchUserMessages(user))
, new Func2<Settings, List<Message>, Pair<Settings, List<Message>>>() {
@Override
public Pair<Settings, List<Message>> call(Settings settings, List<Message> messages) {
return Pair.create(settings, messages);
}
});
}
})
.doOnNext(new Action1<Pair<Settings, List<Message>>>() {
@Override
public void call(Pair<Settings, List<Message>> pair) {
System.out.println("Received settings" + pair.first);
}
})
.flatMap(new Func1<Pair<Settings, List<Message>>, Observable<Message>>() {
@Override
public Observable<Message> call(Pair<Settings, List<Message>> settingsListPair) {
return Observable.from(settingsListPair.second);
}
})
.subscribe(new Action1<Message>() {
@Override
public void call(Message message) {
System.out.println("New message " + message);
}
});
This will create a new user (createNewUser()) and when
it is created and result is returned, it continues to fetch
user messages (fetchUserMessages()) and user settings (fetchUserSettings)
at the same time. It will wait until both actions are completed
and will return a combined result (Pair.create()).
Keep in mind that all of this is happening in the background on a separate thread.
After that, it will print out settings that were received. Finally, the list of messages is transformed into another observable that will start emitting messages themselves instead of an entire list, and each of the messages are printed.
A functional approach
RxJava will be much easier if programmer is familiar with functional programming concepts such as map and zip. Also, they both share lots of similarities of how one would construct a generic logic flow.
How to create a custom observable?
If codes becomes heavily based on RxJava (as for example as Feedpresso is), you will find yourself often in a position where you need to write custom observables so they would fit your flow.
An example of that:
public Observable<String> customObservable() {
return rx.Observable.create(new rx.Observable.OnSubscribe<String>() {
@Override
public void call(final Subscriber<? super String> subscriber) {
// Execute in a background
Scheduler.Worker inner = Schedulers.io().createWorker();
subscriber.add(inner);
inner.schedule(new Action0() {
@Override
public void call() {
try {
String fancyText = getJson();
subscriber.onNext(fancyText);
} catch (Exception e) {
subscriber.onError(e);
} finally {
subscriber.onCompleted();
}
}
});
}
});
}
or a simpler version that doesn't enforce execution of action on a specific thread:
Observable<String> observable = Observable.create(
new Observable.OnSubscribe<String>() {
@Override
public void call(Subscriber<? super String> subscriber) {
subscriber.onNext("Hi");
subscriber.onCompleted();
}
}
);
It is important to note three methods here:
onNext(v)- send a new value to a subscriberonError(e)- notify observer about an error that has occurredonCompleted()- let subscriber know that it should unsubscribe as there won't be any more content from this observable.
Furthermore, it's might be handy to rely on RxJavaAsyncUtil.
Integration with other libraries
As RxJava is becoming more and more popular and becoming de-facto way of doing asynchronous programming on Android, more and more libraries are providing deep integration or reliance on it.
To name a few:
- Retrofit - "Type-safe HTTP client for Android and Java"
- SqlBrite - "A lightweight wrapper around SQLiteOpenHelper which introduces reactive stream semantics to SQL operations."
- StorIO - "Beautiful API for SQLiteDatabase and ContentResolver"
All of them, can make life a lot easier when working with HTTP requests and databases.
Interactive with Android UI
This intro wouldn't be complete without an example, how to use native Android UI elements.
TextView finalText;
EditText editText;
Button button;
...
RxView.clicks(button)
.subscribe(new Action1<Void>() {
@Override
public void call(Void aVoid) {
System.out.println("Click");
}
});
RxTextView.textChanges(editText)
.subscribe(new Action1<CharSequence>() {
@Override
public void call(CharSequence charSequence) {
finalText.setText(charSequence);
}
});
...
Obviously, it's easy to just rely on setOnClickListener
but RxBinding might suit your needs better in a long run as
it allows you to plugin UI into a general RxJava flow.
Tips
Over a time, we have noticed a few things that should be followed while working with RxJava.
Always use error handler
Skipping an error handler like here
.subscribe(new Action1<Void>() {
@Override
public void call(Void aVoid) {
System.out.println("Click");
}
});
is generally not a good idea. An exception thrown in observer or in one of the actions will most likely kill your entire application.
Having a generic handler, would be even better:
.subscribe(..., myErrorHandler);
Extract actions methods
Having lots of inner classes might not look so readable after a while (especially if you are not using RetroLambda).
So a code like this:
.doOnNext(new Action1<Pair<Settings, List<Message>>>() {
@Override
public void call(Pair<Settings, List<Message>> pair) {
System.out.println("Received settings" + pair.first);
}
})
could look a lot better if refactored into this:
.doOnNext(logSettings())
@NonNull
private Action1<Pair<Settings, List<Message>>> logSettings() {
return new Action1<Pair<Settings, List<Message>>>() {
@Override
public void call(Pair<Settings, List<Message>> pair) {
System.out.println("Received settings" + pair.first);
}
};
}
Use custom classes or tuples
There will be many occasions where one value depends on the first one (User and user settings) and you would like to get both of them using two asynchronous requests.
In such cases we would suggest using JavaTuples .
Example:
Observable.fromCallable(createNewUser())
.subscribeOn(Schedulers.io())
.flatMap(new Func1<User, Observable<Pair<User, Settings>>>() {
@Override
public Observable<Pair<User, Settings>> call(final User user) {
return Observable.from(fetchUserSettings(user))
.map(new Func1<Settings, Pair<User, Settings>>() {
@Override
public Pair<User, Settings> call(Settings o) {
return Pair.create(user, o);
}
});
}
});
Lifecycle management
It is going to be often a case when a background process (subscription) is going to survive longer than the Activity or Fragment that contains it. But what if you don't care about the result if user leaves the actvity?
RxLifecycle project will help you here.
Wrap your observable like this (taken from docs), it will unsubscribe when it is being destroyed:
public class MyActivity extends RxActivity {
@Override
public void onResume() {
super.onResume();
myObservable
.compose(bindToLifecycle())
.subscribe();
}
}
Conclusion
This is far from a complete guide about RxJava usage on Android but hopefully it gave a few arguments in favor of RxJava compared to regular AsyncTask.
What is Feedpresso and how is it different?
We often find ourselves in a position where we need to explain to others what is Feedpresso and how it is different from other products available on the market.
We hope that this post will help to clarify that.
What are we?
In Feedpresso you get recommendations for news stories in any language from any source.
This means that to each of our readers, we recommend news stories that they are most likely to like, while letting them to choose their news sources. The any language and any source traits are really important to us as these are usually the biggest obstacles users of other news readers are facing.
We follow these design goals while developing Feedpresso:
- It should be simple to use
- Readers should get relevant content
- It should be available in local languages
These goals lead us to features like:
- Automatic personalisation -- Feedpresso learns from your reading habits 'behind the scenes'. As a result, it provides relevant content while being simple to use.
- A default set of sources and topics for new users in their local language -- we don't want new users to go through set-up just to start reading something (simple and local).
- Aggregated sources -- as relevant content might be scattered all around the web, we want to give our users the tool to find it all in one place.
- Custom sources -- we let users add their own sources of choice, so they would get relevant content easier and would get content from the sources that matter to them faster.
- De-duplication -- helps to find relevant content easier by not showing items that you have already read, as different sources might post the same story.
How are we different?
There are lots of various products on the market that enable you to consume news.
However, there are a few main categories of readers, and we don't really fit in any of them.
Publisher-specific (i.e. brand) readers
These are apps created by a publisher (e.g. BBC or CNN), that include the publishers' own content and send you a constant flux of "breaking news". Some personalisation might be available (e.g. favourite categories).
Obviously, Feedpresso allows you to get content from multiple sites, supports very smart and automatic personalisation.
Local news readers
A category of apps that expose content from one particular site or a few pre-selected sites. They usually have names like "UK news reader" or "Slovak news" and simply aggregate articles from different sites in one place.
These apps usually lack personalisation features: they don't support selecting particular topics or sources to follow, and if they do, it is limited to a hard-coded list.
Topic readers
Theses readers are mainly focused on the topics that you can follow. Popular apps such as Prismatic, Flipboard, Zite and probably lots of others fall into this category.
The problem with this approach is that if you subscribe to a topic like "startups", you will start receiving news from lots of different sites that cover subject in very different levels. So while you might be an expert entrepreneur, you would still receive articles like "Top 5 tips for startups" which is most likely not interesting to you at all.
A better approach here is to pick a specific source that you would like to follow. And that's the route we chose with Feedpresso.
Furthermore, they support usually only English language so you would have a hard time getting content in your local language.
RSS readers
There are lot of RSS readers on the market. A few really great products (e.g. Feedly) and lots of mediocre ones. In most cases, they are simple and straightforward to use. RSS readers let you add any source you would like to read, given that you have an RSS URL available. They are usually great at following specific blogs.
The problem with most of them is that you have to manually tune them until you start getting any content at all. Or worse yet, you can quickly end up in the position where most of your feed is overloaded with content from one specific source (try following blog posts while being subscribed to the BBC).
Obviously, categories help to mitigate this, but it's not something that makes application easy to use.
Feedpresso here provides a number of advantages:
- It provides a default list of content for new readers in their local language, while allowing you to change it.
- Even if there is a mixed content source (topics like criminal activity, foreign affairs, and entertainment), it figures out what you like to read about and will put that content first.
- Tiny blogs will not be swallowed in content from major publishers.
Social readers
These readers usually show content that is shared on social networks like Twitter or Facebook. A few examples of such readers are Facebook itself, Nuzzel or Briefme.
The biggest problem with this approach is that you have to depend on other people to receive a certain piece of story and you must hope that they like the same content as you. If your co-worker shares a story about entertainment, it doesn't mean that you are going to like it. If a football cup gets really trendy between your friends (or globally) you are still going to see those news stories whether you are into football or not.
And what if you like tennis, but none of your friends do? You are not likely to see any news about that.
Also, they suffer from the same problem as topic readers - content in your local language is not available.
Conclusion
We think that Feedpresso has found a unique place in this market: start with a simple and great experience, but do not limit the user and learn from them.
Branch deep links for debug and release on the same device
We have recently adjusted our app's Gradle build scripts to allow us to have multiple versions (e.g. debug and release) installed on one device. One of the problems we stumbled upon was that our Branch deep linking didn't work as we wanted: when creating a Branch link from the debug version of the app, the link would open the release version of the app instead of the debug version. The solution we implemented does not seem obvious nor documented, hence this blog post.
Before we start
This post makes 2 assumptions:
- You already have Branch deep links working for both the Live and Test environments of Branch. I.e. you can open Live links in the release version of app and Test links in test/debug version of your app. But you don't/can't have both versions installed at the same time.
- The different versions of your app have different
applicationIds. In our case, we usecom.feedpresso.mobilefor the release version andcom.feedpresso.mobile.debugfor the debug version of our app.
Setting up the app
Branch's deep links are routed to your app using intent-like URIs where the receiving is determined by the URI's scheme. For example, for Feedpresso we used a scheme like feedpresso://. For this to work for different versions installed at the same time, we need to use different schemes.
First, we set things up on the receiving end -- the app. As per the Branch docs, the scheme your app should listen on is defined in your in AndroidManifest.xml:
<activity ... >
<intent-filter>
...
<data android:scheme="feedpresso" android:host="open" />
...
</intent-filter>
</activity>
To change this per build type, we can use the Gradle's manifestPlaceholders. In our build.gradle, we define the different schemes like this:
defaultConfig {
manifestPlaceholders = [ branchUriScheme:"feedpresso" ]
}
buildTypes {
debug {
manifestPlaceholders = [ branchUriScheme:"feedpresso-debug" ]
}
}
Now we can replace the aforementioned AndroidManifest entry with the following:
<data android:scheme="${branchUriScheme}" android:host="open" />
And the placeholder will be replaced with the right value at build time.
Setting up Branch
Now we'll make sure that Branch links will send the right requests.
- On your Branch Dashboard, make sure you have the appropriate environment selected, e.g. Test.
- go to Settings -> Link Settings and scroll to Android redirects.
- Under Android URI Scheme, enter the scheme name you specified earlier. We went for
feedpresso-debug://.
To prevent Branch from launching Play Store before opening a Branch link for the first time (i.e. the default behavior), we can specify a Custom URL in the same section on the Dashboard.
We set the URL to http://localhost and the Android package name to the packageId used in our debug version, e.g. com.feedpresso.mobile.debug.
That is all the set-up that was required for us. I hope this helps you use Branch for release and debug versions of your app installed on one device.
Re-drawing the Drawer
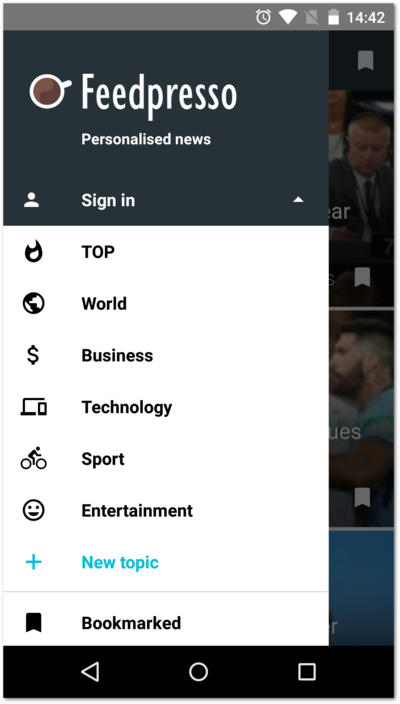
Despite it being a central navigation element, Feedpresso's navigation drawer did not change much since the launch of the app in February 2015. Here's the drawer a month ago:
It's all about topics
The layout here is built around a feature we call topics. When users open Feedpresso, they can easily switch between pre-defined or custom groupings of news feeds, depending on their momentary interests. Besides the sign-in controls, the drawer had an accented action entry for creating new topics, and a Bookmarked entry at the very bottom for accessing saved articles. But the main purpose of the drawer was to switch between topcis easily.
This topic-focused menu layout made perfect sense when we designed the app. We were pretty stoked to give our users the ability to group news sources in their app in any way they wanted. There was just one catch: nobody else cared.
At the very top of its screen hierarchy, Feedpresso has the All stories screen. This is a section of the app where all stories from all of the topics are aggregated together. We treated All stories as a default, 'first' view of the app with the expectation that our users would spend most of their time in a particular topic. We were so sure of the topics feature we didn't even give All stories a menu entry. And oh boy, were we wrong.
As it turns out, most of our users keep coming back to Feedpresso for the All stories screen. For many, the single biggest advantage of our app is its simplicity -- no interest selection, no switching between topics -- just open up and read. From our metrics and after talking to our users we realized that the feature we had considered a filler is actually a killer (ha!). And that for many of our users, the topics are not all that important.
It's all about all the topics
Here's how we incorporated this newly-attained knowledge into the current navigational drawer launched 2 weeks ago:
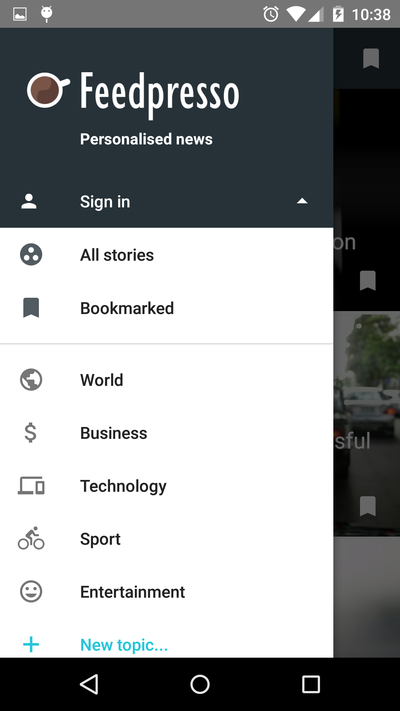
In this layout, we added an entry for All stories and moved the Bookmarked section to a more prominent place. You may also have noticed that the drawer looks more spatious: we followed the material design guidelines to adjust our icons and typography. Same number of entries, yet much more breathing space.
The topics are not going away but we have started treating them as less central. We would like our users to discover and use the feature, but they should be able to use Feedpresso without it.
Usage data and user feedback are crucial for shaping Feedpresso. It's easy to put the Steve Jobs hat on and just follow your intuitions, but nothing beats a good-old data-driven reality check.
Tuning fleet and etcd on CoreOS to avoid unit failures
Here at Feedpresso we are relying on CoreOS to run our services. We have ran Feedpresso on various clouds (Vultr, Google Cloud Compute, Microsoft Azure) and we have learned quite a few things along the way. One of the most frustrating issues that we had to face almost every time was the etcd and fleet runtime behaviour.
In most of theses cases, we had just to appropriately tune them to make everything work again.
In this blog post we won't be claiming that here is everything that you need to know about etcd and fleet tuning or that we know what's exactly happening there and how each of these parameters could impact you.
Consider this post as introduction to things you might want to try out or check first.
VM load and latency
Most of these issues arise when there is considerable latency between node communications and usually this latency comes from high Virtual Machine load. We've seen quite often etcd and fleet failing when CPU was around 100% for a few minutes. Most of these parameters will be coping with that latency.
etcd
As etcd is used by fleet, it is required to get etcd right first before getting to fleet.
On etcd there are basically two properties that you might want to change: heartbeat-interval and election-timeout . The election-timeout should be at least 5 times bigger than heartbeat-interval (5x - 10x bigger).
We've seen quite often in our setups that heartbeat-interval was set to a too low value. When there is a higher load on the machine it started responding slower and it might cause a heartbeat failure. This in turn might cause leader reelection which would impact fleet.
If you seeing something like this:
06:40:30 host fleetd[23463]: INFO client.go:292: Failed getting response from http://localhost:2379/: cancelled
06:40:30 host fleetd[23463]: INFO client.go:292: Failed getting response from http://localhost:2379/: cancelled
06:40:30 host fleetd[23463]: INFO client.go:292: Failed getting response from http://localhost:2379/: cancelled
06:40:45 host fleetd[23463]: INFO client.go:292: Failed getting response from http://localhost:2379/: cancelled
06:40:45 host fleetd[23463]: INFO client.go:292: Failed getting response from http://localhost:2379/: cancelled
or
googleapi: got HTTP response code 500 with body: {"error":{"code":500,"message":""}}
when you are using fleetctl or etcdctrl it is quote likely that you need to bump your heartbeat-intervalvalue_.
This can be done like this in your cloud-config file:
#cloud-config
coreos:
etcd2:
heartbeat-interval: 600
election-timeout: 6000
Obviously, you need to fine-tune them to your set up. If those values are left to be to high, you might not be able to cope with cluster failures very well.
Fleet
Fleet is quite sensitive to response times from etcd as well. If it loses connection to etcd and then recovers it, it would restart all units on that machine and this might not be the thing you would want.
For example, the high database usage would cause a latency increase and that would make fleet lose connection to etcd. Then when connection is restarted all units are going to be restarted together with the DB that is obviously in use at that moment.
In fleet logs it usually looks like this:
Apr 09 21:20:31 machine1 fleetd[21543]: INFO engine.go:208: Waiting 25s for previous lease to expire before continuing reconciliation
Apr 09 21:20:31 machine1 fleetd[21543]: INFO engine.go:205: Stole engine leadership from Machine(9c33fade6ddf46448fcbacd8ed8495a5)
Apr 09 21:20:30 machine1 fleetd[21543]: ERROR engine.go:218: Engine leadership lost, renewal failed: 101: Compare failed ([13675908 != 1
or
fleetd[615]: ERROR reconcile.go:120: Failed fetching Units from Registry: timeout reached
fleetd[615]: ERROR reconcile.go:73: Unable to determine agent's desired state: timeout reached
fleetd[615]: INFO client.go:292: Failed getting response from http://etcd-b1.<OUR_CLUSTER_DOMAIN>:4001/: cancelled
fleetd[615]: ERROR engine.go:149: Unable to determine cluster engine version
fleetd[615]: INFO client.go:292: Failed getting response from http://etcd-b1.<OUR_CLUSTER_DOMAIN>:4001/: cancelled
fleetd[615]: INFO engine.go:81: Engine leadership changed from e9fc4f64602545aca6fbab041d4abae9 to 4ddd4e13813f4e11bbf96622bf3aefe0
fleetd[615]: ERROR reconcile.go:120: Failed fetching Units from Registry: timeout reached
fleetd[615]: ERROR reconcile.go:73: Unable to determine agent's desired state: timeout reached
fleetd[615]: INFO client.go:292: Failed getting response from http://etcd-a1.<OUR_CLUSTER_DOMAIN>:4001/: cancelled
fleetd[615]: INFO client.go:292: Failed getting response from http://etcd-a1.<OUR_CLUSTER_DOMAIN>:4001/: cancelled
fleetd[615]: INFO client.go:292: Failed getting response from http://etcd-a1.<OUR_CLUSTER_DOMAIN>:4001/: cancelled
fleetd[615]: INFO client.go:292: Failed getting response from http://etcd-a1.<OUR_CLUSTER_DOMAIN>:4001/: cancelled
fleetd[615]: INFO client.go:292: Failed getting response from http://etcd-a1.<OUR_CLUSTER_DOMAIN>:4001/: cancelled
fleetd[615]: WARN job.go:272: No Unit found in Registry for Job(spark-tmp.mount)
fleetd[615]: ERROR job.go:109: Failed to parse Unit from etcd: unable to parse Unit in Registry at key /_coreos.com/fleet/job/spark-tmp.mount/object
fleetd[615]: INFO client.go:292: Failed getting response from http://etcd-a1.<OUR_CLUSTER_DOMAIN>:4001/: cancelled
fleetd[615]: INFO manager.go:138: Triggered systemd unit spark-tmp.mount stop: job=1723248
fleetd[615]: INFO manager.go:259: Removing systemd unit spark-tmp.mount
fleetd[615]: INFO manager.go:182: Instructing systemd to reload units
In cases like this, you would need to tune engine-reconcile-interval, etcd-request-timeout and agent-ttl. Most likely you will want to bump etcd-request-timeout. engine-reconcile-interval determines how often your fleetd consults with etcd for unit changes in etcd. It might be good to increase this value to reduce the load on etcd at the expense of how fast changes are picked up.
It is not completely clear what agent-ttl does, but since agent is responsible for actual running and stopping of units on the system, this value is used to determine if it is still possible to do that. In case the agent is dead, it would probably start a new one.
Cloud config could look like this:
coreos:
fleet:
public-ip: $private_ipv4
metadata:
engine-reconcile-interval: 10
etcd-request-timeout: 5
agent-ttl: 120s
Documentation
For more information it would be worth reading these articles:
- https://github.com/coreos/fleet/blob/master/Documentation/architecture.md
- https://github.com/coreos/fleet/blob/master/Documentation/deployment-and-configuration.md
- https://github.com/coreos/etcd/blob/master/Documentation/configuration.md
- https://github.com/coreos/etcd/blob/master/Documentation/tuning.md
Also, it is worth taking a look into these issues:
2 things you need to know about new Android permissions in Marshmallow as a developer
Android is releasing a new permission model with Marshmallow. A bit ago, we were searching, how things are going to change for us as developers. The change is, that now, permissions are going to be requested at runtime instead of being requested during an install. However, there are two things to know before diving deeper.
targetSdkVersion
As long as you do not set the target SDK version to 23, you are fine - the Google Play store and Android are going to use the old permission model and there should be no need of changes on your side. The permissions are going to be requested during install time as before.
Normal permissions
You are not going to need to do any changes, if all of the permissions that you are using are in a group of Normal Permissions. Normal Permissions are granted automatically during install time. If you use only these, there won't be any SecurityException during runtime regarding them. Also, users cannot revoke them as well.
Other
For all the other things you are going to need to go through Permissions documentation to know how to handle requests for these permissions properly.
Introducing the Feedpresso Blog
Recently, we found that we didn't have any good means to communicate and explain our decisions and experiences. This new blog, we hope, is going to fill that need.
For example, we have been working quite a lot on tiny and subtle changes on the design and overall experience of Feedpresso but our Facebook page doesn't really fit these kind of posts where people like to receive short messages and shout outs.
As we are working on various things at the moment we keep discovering and learning knowledge that might not be so easy to find on the web. We would like to share our discoveries about Android, CoreOS, Python and other parts of the stack that we are using at the moment.
Tadas Šubonis, Ernest Walzel (Founders)
subscribe via RSS